
Introduction
Confluence is a perfect tool for online team collaboration. It makes it easy for everyone on the team to add information. Due to a lack of structure the team wiki may pretty fast become a place where it gets more and more difficult to add information so that it can be found in a reasonable amount of time. It also gets harder for team members to know where to add new content.

In the last article, Finding without Searching, we examined the different ways of information seeking needs and behaviors. We came to the conclusion that categorizing information is the key to understanding and to support the users of an information system. In the context of a project the users are first and foremost the members of the teams and stakeholders with access to the project wiki.
Let's examine how to apply categories with tools provided by Confluence and projectdoc.
Categories
If you add a page to another page in your wiki as a child, you are building a hierarchy and therefore categorize your content. The parent relationship is quite strong. While a parent may have many children, each child has exactly one parent. And although there lies some value in defining your categories mutual exclusive, you should not feel to be bound to. But since each child cannot have more than one parent, you would need to be strict by design.
A Category enables the team to define a classification outside a single page hierarchy. A document may be assigned to multiple categories and therefore may have multiple semantic parents.
The information is attached to a category by selecting it's name as a value for the Categories property.
The category is itself documented by a document. The document automatically lists all documents associated with it. The following example shows the document for the category 'AtlasCamp'. The example shows two documents attached to this category.
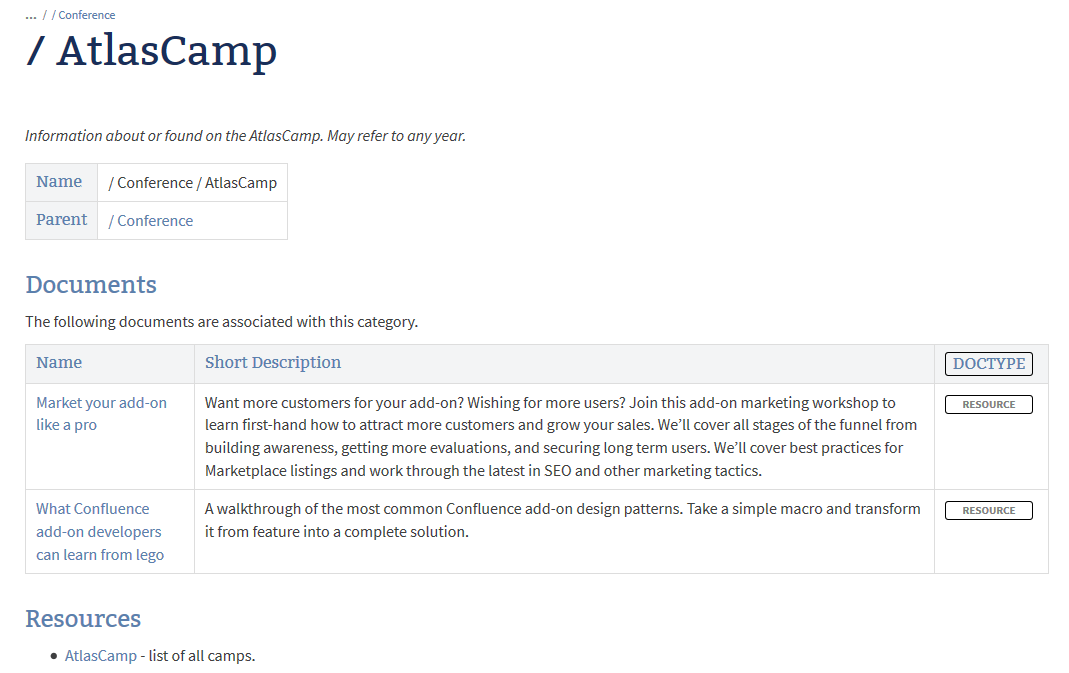
Categories define navigation paths through your documentation. It is typically useful to define the major categories that are relevant for your team and project. Creating them adhoc usually yields inferior results.
Hierarchies and Queries
Note that you can use hierarchies in your queries!
If you want to select all conferences (as shown in the example above), use Ancestor Queries.
To list all documents with category 'Conference' or any subcategory, use the following constraint (e.g. Display Table Macro):
$<Categories> = °Conference°
It is also helpful to define your category hierarchies more wide than deep.
Categories over Topics
Whenever you think to create a topics page for collection resources for a given topic, consider to create a category. The category document is usually good place to define and collect resources for a topic.




