
 In the article On Names we showed that having an accurate name for domain objects is essential to provide scope and control. Now we want to concentrate on how to find names and use them consistently in our projects.
In the article On Names we showed that having an accurate name for domain objects is essential to provide scope and control. Now we want to concentrate on how to find names and use them consistently in our projects.
We will have a look at the language we use in our projects and provide rules how to use names in our code while adhering to naming conventions.
Ubiquitous Language
It is necessary that the technical part and the business part (i.e. domain experts) of the team use the same language. This reduces the risk of misunderstanding and helps to create a common view on the domain and the goals of the project.
Domain Driven Design
Eric Evans calls this language used by the whole team Ubiquitous Language.
The vocabulary of the UBIQUITOUS LANGUAGE includes the names of classes and prominent operations. The LANGUAGE includes terms to discuss rules that haven been made explicit in the model. It is supplemented with terms from high-level organizing principles imposed on the model [...].
Eric Evans. Domain Driven Design, p. 25
These are the steps defined by Eric Evans that lead the team to a Ubiquitous Language:
Eric Evans. Domain Driven Design, p. 26f - reformatted to a list.
- Use the model as the backbone of a language.
- Commit the team to exercise the language relentlessly in all communication within the team and in the code.
- Use the same language in diagrams, writing, and especially speech.
- Iron out difficulties by experimenting with alternative expressions, which reflect alternative models
- Then refactor the code, renaming classes, methods, and modules to conform to the new model.
- Resolve confusion over terms in conversation, in just the way we come to agree on the meaning of ordinary words.
- Recognize that change in the UBIQUITOUS LANGUAGE is a change to the model.
[So it is the work of the domain experts] to object to terms or structures that are awkward or inadequate to convey domain understanding; [and it is the work of developers to] watch for ambiguity or inconsistency that will trip up design.
Eric Evans. Domain Driven Design, p. 27
Glossary
One tool I find very useful to create the Ubiquitous Language is a glossary. This should be accessible to everyone in the team and everyone should in the team should be able to easily edit the terms or add additional information to it. So a technical tool like a Wiki, where each term is defined on its own page, is very handy. Tag or categorize each page as a term of the glossary so that the index of terms can be automatically created. Do not be hesitant to add information to the term that you are not quite sure of. Add it and mark it as experimental, describe why you are not sure of the term or its definition. This allows others to contribute.
In larger projects you may want to follow a more formal way. Daryl Kulak and Eamonn Guiney describe a way to create and elaborate on use cases in their book Use Cases - Requirements in Context. The process of specifying use cases has the following phases, which I interpret in the context of defining a term for the glossary:
- Facade - you found a term and add it with brief information to the glossary. There is no need to try to be precise or add any information at all beside its name and the context where it has been discovered.
- Filled - you add any information to the term you can think of. The goal is to find the whole scope for the term.
- Focused - you prune your findings and may add further terms to the glossary that where first thought to be part of the term, but described autonomous aspects. Remove any redundancies that where produced during the Filled Phase.
- Finished - polish the term, add references to related terms, contrast the term to other terms it may be confused with. Add alternative terms that are treated as synonyms, etc. The point it to integrate the term in the context of the Ubiquitous Language. Every term is now precise and coherent.
Specification by Example
Other tools to establish and use the Ubiquitous Language in your project are Agile Acceptance Testing, Specification by Example or Behaviour Driven Design (BDD). These tools help to close the communication gap between the different roles within a team (developers, product manager, domain expert, customer, tester, ...) and further ensure that the common language is used in discussions, specifications and coding. They further enforce a truly shared and consistent understanding of the domain. If you are not familiar with these kind of tools, I recommend to read one of Gojko Adzic's books: Specification by Example or Bridging the Communication Gap. Gojko Adzic also provides an interesting newsletter called Impact that provides updates on the matter.
Our testdoc-tools also help to use the project's language within tests written with JUnit. This may be an option for those that do not want to use BDD tools, but are sensitive to have readable names for test cases and generate reports to make them available to non-programmers.
At this point we have begun to establish a common language and try to consistently use the terms of our domain. Let's switch to coding and rules how to transfer this language on this very fundamental area of software projects.
Naming Software Elements
What are the rules to make up good names for your software elements?
Briefly:
The name of a variable, function, or class, should answer all the big questions. It should tell you why it exists, what it does, and how it is used.
Robert C. Martin. Clean Code
Concepts
In Chapter 2 of Clean Code, Tim Ottinger writes a lot of detailed information about Meaningful Names. He covers the following concepts:
- Use Intention-Revealing Names - The goal here is defined in the quote above, but since this is - in our view - the most important point, we cite it again: "The name of the variable, function, or class, should answer all the big questions. It should tell you why it exists, what is does, and how it is used." (p. 18)
- Avoid Disinformation - "Programmers must avoid leaving false clues that obscure the meaning of code. [...] Beware of names which vary in small ways. [...] Spelling similar concepts similarly is information. Using inconsistent spelling is disinformation." (p. 19f)
- Make Meaningful Distinctions - do not introduce an arbitrary name for the same concept just to distinguish two of them in a given context. Try hard to find the difference and provide meaningful name.
- Use Pronounceable Names - since they are part of the Ubiquitous Language each team member has to use them when they speak to each other.
- Use Searchable Names - if you want to search for a particular name, names like
eorlistare not easily searchable. - Avoid Encodings - these make the domain language more complicated in the code.
p_customerfor a private field?IPhonefor an interface for a phone? Also do not use suffixes likeImpl. Name what the intention of the artifact is. - Avoid Mental Mapping - do not use a meaningless name that has to be mapped to a construct of the domain by a programmer. Programmers should write code that others can easily understand.
- Don't Be Cute - this also takes place if a name is not taken from the Ubiquitous Language. Do not use slang or cultural dependent names. "Say what you mean. Mean what you say." (p. 26)
- Pick One Word per Concept - the glossary will help.
- Don't Pun - "[a]void using the same word for two purposes." (p. 26)
- Use Solution Domain Names - it is a good practice to use terms from the solution domain, like names from pattern (e.g.
Factory) or common programming constructs (likeStack,QueueorList), since they reveal the intent of the structure. This terms get part of the Ubiquitous Language, if they are used outside the coders domain. - Use Problem Domain Names - simply use the Ubiquitous Language.
- Add Meaningful Context - if you have a street and a city that is part of an address, make them elements of a class
Address. - Don't Add Gratuitous Context - "Shorter names are generally better than longer ones, so long as they are clear. Add no more context to a name than is necessary." (p. 30)
Rules
At the end of the book Robert C. Martin boils these advices down to seven rules to follow (Clean Code, p. 309 - 313):
- Choose Descriptive Names
- Choose Names at the Appropriate Level of Abstraction
- Use Standard Nomenclature Where Possible
- Unambiguous Names
- Use Long Names for Long Scopes
- Avoid Encodings
- Names Should Describe Side-Effects
I want to stress the last point of the list. If a method getInputStream not only returns a reference to an input stream, but also creates it on each call, adding the stream to the list of streams within the addressed object, the method should read addAndReturnNewInputStream. Changing the state of the addressed object has to be clear by reading the API.
The third point Use Standard Nomenclature Where Possible not only refers to the Ubiquitous Language but also carries us directly to Naming Conventions. But before we switch to this topic, we want to introduce a small tool to check the terms used in your code: tag clouds.
Tag Clouds
Tag clouds on your code help to have a view on the language actually used in your code. They also visualize the proportion of domain specific terms to technical terms.

A tool to include into your Maven build process to generate a report within your Maven Site is our tagcloud plugin.
Naming Conventions
Naming conventions are part of the project's coding conventions that make the artifacts of a team resemble the work of a single man. This uniformity is a quality attribute that helps to understand written information more easily and therefore reduces the cost of maintenance of software in particular. Naming conventions are usually influenced by the programming language used. In his book Effective Java, Joshua Bloch provides some information about naming conventions using Java.
First of all naming conventions are defined in the Java Language Specification (JLS), particularly in chapter 6.8. In his book, in Item 56: Adhere to generally accepted naming conventions (Second Edition, p. 237), Joshua Bloch divides these conventions into two categories: typographical and grammatical.
Typographical Naming Conventions
The kinds of conventions are often not controversial and easily to follow.
You should rarely violate them and never without a good reason. [... Since] violations have the potential to confuse and irritate other programmers who work with the code and can cause faulty assumptions that lead to errors.
Joshua Bloch. Effective Java, p. 237
I do not reiterate about the details on these conventions, as they are readily available on the web (JLS, 6.8). For some more details please refer to Joshua Bloch's book. Here is a table of examples for each identifier type, found on page 238, to give a short overview on these rules:
| Identifier Type | Examples |
|---|---|
| Package | com.google.inject, org.joda.time.format |
| Class or Interface | Timer, FuturTask, LinkedHashMap, HttpServlet |
| Method or Field | remove, ensureCapacity, getCrc |
| Constant Field | MAX_VALUE, NEGATIVE_INFINITY |
| Local Variable | i, xref, houseNumber |
| Type Parameter | T, E, K, V, X, T1, T2 |
Grammatical Naming Conventions
Grammatical naming conventions include rules such as classes and interfaces are named like nouns, while methods are named like verbs. Methods that return a boolean value usually start with the prefix is or has. Accessors in the context of Java Beans are prefixed with get and set, while outside this context, if no setter is provide, methods may lack this prefix for the sake of better readability.
if(car.speed() > 2 * SPEED_LIMIT)
generateAudibleAlert("Wacht out for cops!");
Example taken from Effective Java, p. 239.
As you can see, in opposition to typographical naming conventions, grammatical naming convention can be the source for controversial discussions. ;-)
Another set of grammatical naming conventions used in the Java API are the use of toType (as in toString) to convert an object to an independent instance of another type. asType (as in asList) to return a view on the given object with another type. There are also conventions to return a primitive Type (e.g. intValue) or to name factory methods (e.g. valueOf).
And there are many more naming conventions found in Java code. All these conventions try to reduce the need to reinvent the wheel or the risk to name the same concept differently within a project. This follows the Principle of least Astonishment and helps using an API that follows clear conventions as well as reducing maintenance costs.
Conclusion
We have shown the relevance of a Ubiquitous Language and provided information on how to establish and use it within your projects. This language has impact on three areas of a software project:
- reduce the communication gap within a team
- name elements of the domain within your code
- use naming conventions consistently
In the next part of this short series we will introduce the naming conventions we use in our projects.
A lot of well-known professionals in the software industry stress the importance of naming elements precisely, based on the currently best understanding of the problem domain. This goes all the way from the central concepts dealt with in the project, down to the naming of variables in the source code.
In the foreword of Robert C. Martin‘s book Clean Code you find this gem of wisdom:
You should name a variable using the same care with which you name a first-born child.
James O. Coplien
One reason is maintenance:
Names in software are 90 percent of what makes software readable.
Robert C. Martin
Since software developers read foreign code prior to understanding it and reading code is much more often done than writing it, it makes perfect sense to follow James Coplien‘s advice.
Management and the Urgency of accurate Names
It is often difficult to explain this importance to the management. They want to get things done. Starting a project, maintenance seems to be a beast on the horizon that can be dealt with later. So the technical debt is raised with the first key strokes on a new project.
Names in a software projects have basically two goals:
Control
Naming things is to control them.
Names are the most important attributes of things and events.
Jaroslav Tulach
Perception
Here is a story of the London Zoo that shows the significance of names:
The Zoological Society of London tried to find out, which animals are the most liked by the zoo visitors. They gave each visitor a stack of postcards, each showing a single animal. The stack should be prioritized with the most liked animal on top and the least liked at the bottom. The other day the experiment was repeated, but this time the names of the animals where printed on the cards.
While on the first day a cute little animal made it to a front position, a nasty snake was voted to the bottom. It turned out that after knowing that the cute little animal was a kind of rat and the snake was called Royal Python, the ranking was quite different on the second day: The Royal Python was higher ranked than the nasty Opossum.
Source: Richard David Precht, Warum gibt es alles und nicht nichts?, paraphrased and translated
Names build images and advance expectations. They make how we look at the entities they define, how we assume to handle them and expect their behaviour in response to our actions.
This is also true in the field of software development. If you speak about a test mock and really mean a fake object, this can be confusing to the listeners (at least for those that have read xUnit Test Patterns by Gerard Meszaros). Developers may watch out for verification methods in the mock, but since it is a fake, they won’t find them.
If you call a database user database, but you store products in it, this is confusing, too. Developers will try to store user in the database, but won’t find a table that fits. Other developers might actually search for a place to store products, but won’t have a look at the tables of the user database.
So names make a difference: They control how things are perceived.
Expectations
A repository is expected to store things of a given type. An action listener is expected to listen to actions, a factory is expected to produce something. A button is expected to be pushable, a display to be able to show information.
So names make a difference: They control how things are used.
Accurate Names
You have to find an accurate name for a domain object, or how Mark Twain puts it:
The difference between the right word and the almost right word is the difference between lightning and a lightning bug.
Mark Twain
If the team has to guess names, since no domain expert is available or equally worse, the domain expert has no names for the concepts in the problem domain, there is the danger for the development team to constantly revisit the names of their types without getting any real ground.
It is often more easy to recognize that a given name does not fit, but it is sometimes very hard to find the correct term. But in the end, if you still have not found a name that fully expresses the essence of an entity, you have to go with what you actually made up and repeat your endeavour of finding a matching name until it eventually fits, paying back the technical debt.
Scope
White Spots and Uncertainty
Naming things raises above the source code level and goes deeper than just maintenance issues. It is also about the scope of the project. If you cannot define the scope of the project, name the central pieces, it is like a 19th century map with a lot of white spots.
Source: Wikipedia
The white spots are discomforting. One does not know what’s inside. It’s a source of danger. Cartographers depicted such uncertainty with the phrase “Here be dragons“. So it is hard to comprehend the target and scope of the whole venture. Every white area is a risk for the team to misunderstand something or make something up that is not true at all.
Source: Wikipedia
Killer Joke Pattern
Management sometimes underestimate the power of their technical team knowing precisely what the intended goal of a project is. I often see that the management appoints partial tasks to individuals without any of them understanding the big picture. This reminds me of Monty Pythons‘ Killer Joke (you may watch this as a video on YouTube), where each member of the translation team was given only a fragment to translate in order to not get killed. Maybe this would give a nice name to this “anti-pattern”, not telling the team the whole story: Killer Joke Pattern. ![]()
Scoping the Project
So what to do to tell the whole story? Alistair Cockburn advices us to use outermost use cases. This use cases, usually a handful for a system, define the whole scope of the project.
These outermost use cases are very useful in holding the work together, and I highly recommend writing them [for the following reasons:]
Alistair Cockburn, Three Named Goal Levels. Writing Effective Use Cases
- They show the context in which user goals operate.
- They show life-cycle sequencing of related goals.
- They provide a table of contents for the lower-level use cases […].
The uses cases map the scope of the project and give these maps a name to control them.
So the intention to give scope to a project also is a form of the desire to be in control.
Conclusion
Names are essential since they provide scope and control the artifacts having a name. In the next post, called On Naming, we will discuss how to find names and use them consistently in our projects.
 Unit-Testing is often a simple task, if you have small units that are designed to be tested in isolation easily. These units in common applications often have no complex business logic and the edge cases are quickly pinned down and dealt with individually, unit by unit.
Unit-Testing is often a simple task, if you have small units that are designed to be tested in isolation easily. These units in common applications often have no complex business logic and the edge cases are quickly pinned down and dealt with individually, unit by unit.
But there are a couple of responsibilities (mostly methods) in Java that are to be tested the same way for each implementation.
These are
equalshashCodetoString(i.e. check no runtime exception is raised)compareTo- Serialization
We will show in this article, how these responsibilities can be tested declaratively without writing individual test cases using JUnit theories.
For demonstration we will add methods to the following simple point class. For brevity we do not add getters to the fields and omit any Javadoc comments. For some obscure reasons we allow the coordinates to have a value of null.
public final class Point {
private final Integer x;
private final Integer y;
public Point(final Integer x, final Integer y) {
this.x = x;
this.y = y;
}
}
equals and hashCode
So let’s add a equals method to the class.
import org.apache.commons.lang.ObjectUtils;
public final class Point {
private final Integer x;
private final Integer y;
public Point(final Integer x, final Integer y) {
this.x = x;
this.y = y;
}
@Override
public int hashCode() {
int result = 17;
result = 37 * result + ObjectUtils.hashCode(x);
result = 37 * result + ObjectUtils.hashCode(y);
return result;
}
@Override
public boolean equals(final Object object) {
if (this == object) {
return true;
}
else if (object == null || getClass() != object.getClass()) {
return false;
}
final Point other = (Point) object;
return (ObjectUtils.equals(this.x, other.x)
&& ObjectUtils.equals(this.y, other.y));
}
}
Since we allowed coordinate values to be null, we use ObjectUtils from Apache’s commons-lang library.
Usually, for every class that supportes equals and therefore hashCode, we have to write some tests with typical edge values. What has to be tested is stated in the API documentation for Object. And this is the same for all implementations.
These are the constraints for equals:
- It is reflexive: for any non-null reference value x, x.equals(x) should return true.
- It is symmetric: for any non-null reference values x and y, x.equals(y) should return true if and only if y.equals(x) returns true.
- It is transitive: for any non-null reference values x, y, and z, if x.equals(y) returns true and y.equals(z) returns true, then x.equals(z) should return true.
- It is consistent: for any non-null reference values x and y, multiple invocations of x.equals(y) consistently return true or consistently return false, provided no information used in equals comparisons on the objects is modified.
- For any non-null reference value x, x.equals(null) should return false.
And for hashCode:
- Whenever it is invoked on the same object more than once during an execution of a Java application, the hashCode method must consistently return the same integer, provided no information used in equals comparisons on the object is modified. This integer need not remain consistent from one execution of an application to another execution of the same application.
- If two objects are equal according to the equals(Object) method, then calling the hashCode method on each of the two objects must produce the same integer result.
- It is not required that if two objects are unequal according to the equals(java.lang.Object) method, then calling the hashCode method on each of the two objects must produce distinct integer results. However, the programmer should be aware that producing distinct integer results for unequal objects may improve the performance of hash tables.
This adds up to a couple of unit tests for each class. Writing these tests is cumbersome and error-prone.
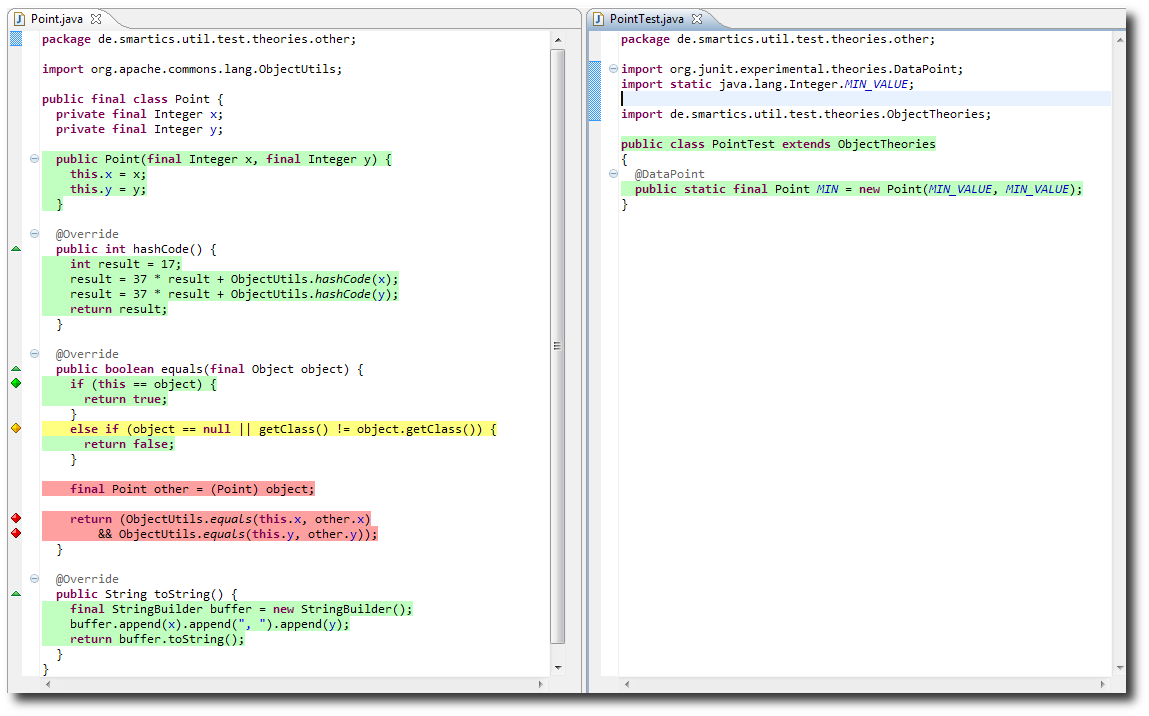
Fortunately JUnit provides a features called Theories that help to specify the rules given above once and run these rules (or theories) against any implementation. All you have to do is to create instances for the edge values and tell JUnit to run the theories against them. So the work we have to do, using an implementation of ObjectTheories is this:
import org.junit.experimental.theories.DataPoint;
import static java.lang.Integer.MIN_VALUE;
import static java.lang.Integer.MAX_VALUE;
import de.smartics.util.test.theories.ObjectTheories;
public class PointTest extends ObjectTheories {
@DataPoint
public static final Point MIN = new Point(MIN_VALUE, MIN_VALUE);
@DataPoint
public static final Point MIN_MAX = new Point(MIN_VALUE, MAX_VALUE);
@DataPoint
public static final Point MAX = new Point(MAX_VALUE, MAX_VALUE);
@DataPoint
public static final Point EQUAL = new Point(MAX_VALUE, MAX_VALUE);
}
The theory tests that equals and hashCode are implemented as required by the rules of the Object class shown above. This is the result of the run:
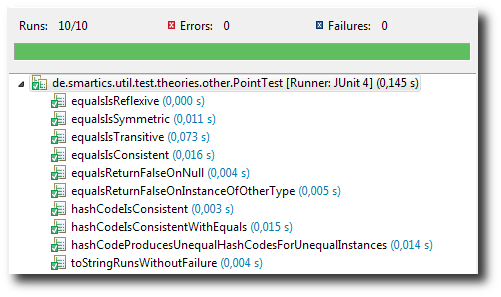 Everything’s green. You see the names of the tests that have been run. It also tests that the
Everything’s green. You see the names of the tests that have been run. It also tests that the toString method. We still only have the default implementation and now add the following toString implementation:
@Override public String toString() {
final StringBuilder buffer = new StringBuilder();
buffer.append(x.intValue()).append(", ").append(y.intValue());
return buffer.toString();
}
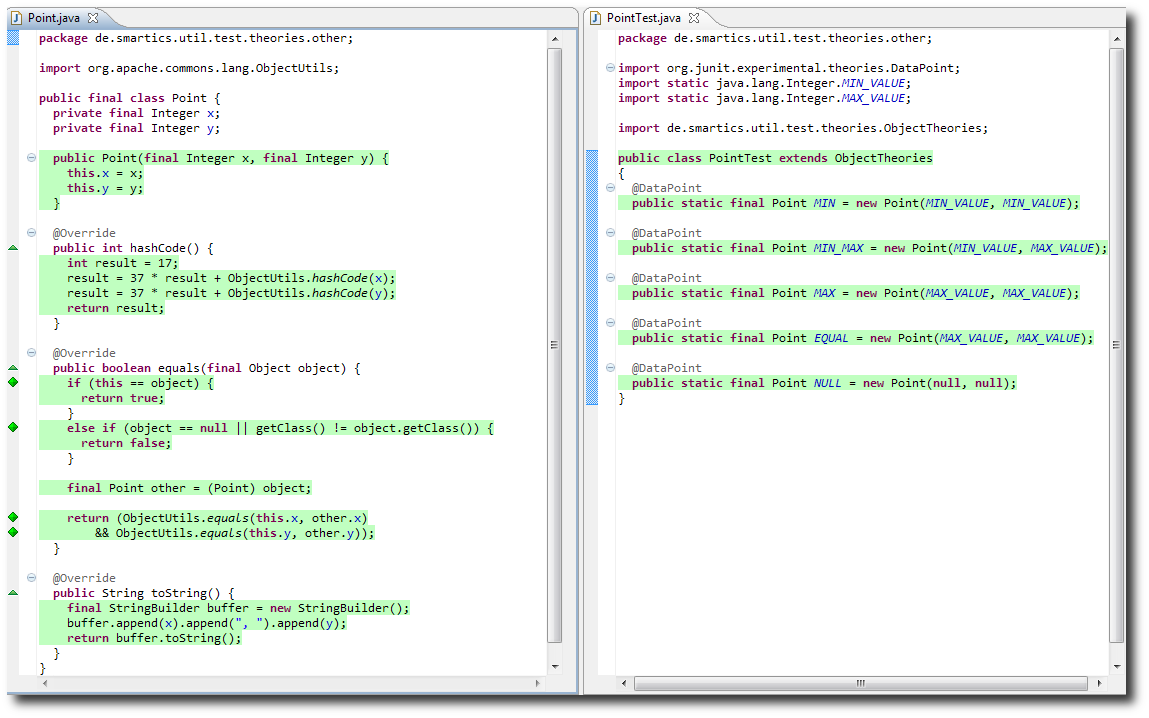
And add a new data point to our test:
@DataPointpublic static final Point NULL = new Point(null, null);
And see the toString test fail:
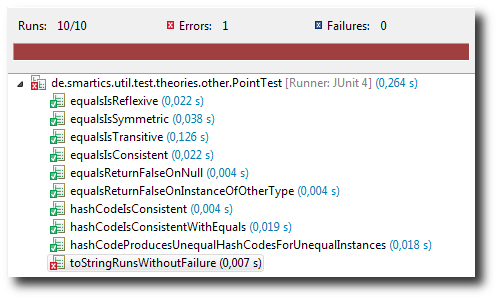
We just wanted to show that the theories really find bugs.![]()
An easy fix (a better fix may be to not allow null values, but we do not want to make this article longer than it actually is – add a check to the constructor and the read method for serialization – we cover serialization in the next section):
@Override
public String toString() {
final StringBuilder buffer = new StringBuilder();
buffer.append(x).append(", ").append(y);
return buffer.toString();
}
At this point you may find code coverage a handy tool to check that every case has been checked by the theories. Let’s check if using a single data point is not enough:
No, it isn’t.![]()
With all data points as shown above:
Yes, it is! ![]()
compareTo
Implementing a Comparable has similar constraints as equals to be met.
We add the comparable interface to our Point class:
public final class Point implements Comparable<Point> {
...
public int compareTo(final Point o) {
int compare = ObjectUtils.compare(this.x, o.x);
if (compare == 0) {
compare = ObjectUtils.compare(this.y, o.y);
}
return compare;
}
Here is the solution using CompareToTheory. Let’s start with just one data point:
import static java.lang.Integer.MIN_VALUE;
import org.junit.experimental.theories.DataPoint;
import de.smartics.util.test.theories.CompareToTheory;
public class PointCompareToTest extends CompareToTheory<Point> {
@DataPoint
public static final Point MIN = new Point(MIN_VALUE, MIN_VALUE);
}
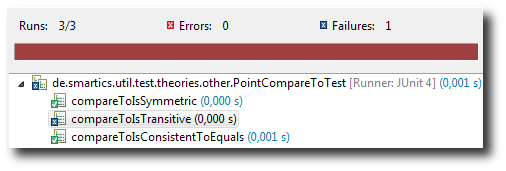
As we can see, the test compareToIsTransitive signals a test failure, since one data point is not enough to check transitivity for compareTo.
So let’s add two additional data points:
import static java.lang.Integer.MAX_VALUE;
import static java.lang.Integer.MIN_VALUE;
import org.junit.experimental.theories.DataPoint;
import de.smartics.util.test.theories.CompareToTheory;
public class PointCompareToTest extends CompareToTheory<Point> {
@DataPoint
public static final Point MIN = new Point(MIN_VALUE, MIN_VALUE);
@DataPoint
public static final Point MIN_MAX = new Point(MIN_VALUE, MAX_VALUE);
@DataPoint
public static final Point MAX = new Point(MAX_VALUE, MAX_VALUE);
}
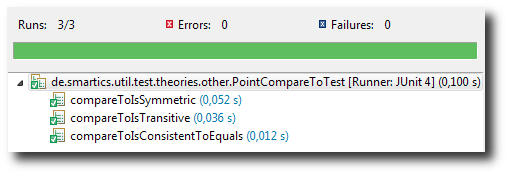
Again, with only some edge values are defined, JUnit theories do their work.
You like typos? ![]()
public int compareTo(final Point o) {
int compare = ObjectUtils.compare(this.x, o.x);
if (compare == 0) {
compare = ObjectUtils.compare(this.x, o.y); // <-- TYPO!
}
return compare;
}
Gotcha!
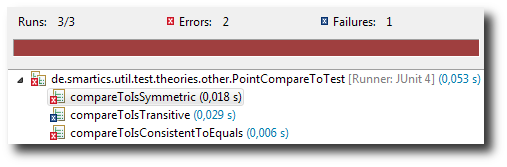
compareTo is no longer symmetric nor transitive.
One Word of Warning
Please note that it depends on your data points (and typos ;-)), which tests fail. For more complex data types, please check with a coverage tool that all paths have been covered!
Theories just check that the implementation adhere to the rules stated by the Java API.
In the example above we just check symmetry and transitivity. We do not check business rules as: is point (0, 1) really smaller than point (1,2)? The same is true for equals: we do not check if two instance that should be equal as to the business rules, are really equal.
Add these tests, if you need to!
Serialization
You might already guess, how the test case based on SerializationTheory looks like:
import static java.lang.Integer.MAX_VALUE;
import org.junit.experimental.theories.DataPoint;
import de.smartics.util.test.theories.SerializationTheory;
public class PointSerializationTest extends SerializationTheory {
@DataPoint
public static final Point NULL = new Point(null, null);
@DataPoint
public static final Point MAX = new Point(MAX_VALUE, MAX_VALUE);
}
This time we do test-first and run into an error: our class does not implement the Serializable interface.
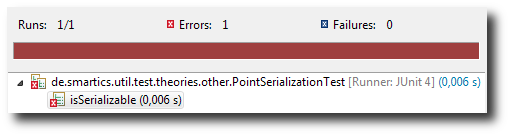
Let’s add the missing interface and we have finally the complete Point class:
import java.io.Serializable;
import org.apache.commons.lang.ObjectUtils;
public final class Point implements Serializable, Comparable<Point> {
private static final long serialVersionUID = 1L;
private final Integer x;
private final Integer y;
public Point(final Integer x, final Integer y) {
this.x = x;
this.y = y;
}
public int compareTo(final Point o) {
int compare = ObjectUtils.compare(this.x, o.x);
if (compare == 0) {
compare = ObjectUtils.compare(this.y, o.y);
}
return compare;
}
@Override
public int hashCode() {
int result = 17;
result = 37 * result + ObjectUtils.hashCode(x);
result = 37 * result + ObjectUtils.hashCode(y);
return result;
}
@Override
public boolean equals(final Object object) {
if (this == object) {
return true;
}
else if (object == null || getClass() != object.getClass()) {
return false;
}
final Point other = (Point) object;
return (ObjectUtils.equals(this.x, other.x)
&& ObjectUtils.equals(this.y, other.y));
}
@Override
public String toString() {
final StringBuilder buffer = new StringBuilder();
buffer.append(x).append(", ").append(y);
return buffer.toString();
}
}
Let’s run the test one more time to be sure:
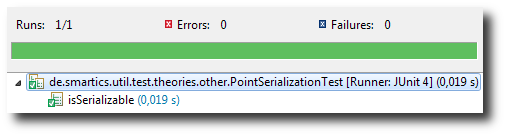
You may ask yourself, how do I get this?
![]()
If you are using Maven, integration in your build process is quite simple:
<dependency> <groupId>de.smartics.util</groupId> <artifactId>smartics-test-utils</artifactId> <version>0.3.3</version> <scope>test</scope> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.8.2</version> <scope>test</scope> </dependency>
Note to update versions as appropriate.
The artifact is not available on the standard repositories. Please have a look at our instructions on how to access artifacts on our repository.
If you are not using Maven, please download the artifact from our repository and check the dependencies manually. Either by inspecting the pom.xml or the dependency report on the project’s site.
For more details on this library, please refer to smartics Test Utils.
Last week I watched a video showing a talk by Kevin Bourrillion introducing Guava, a set of open source core libraries used internally by Google.
Kevin Bourrillion mentioned the library's Preconditions class that is closely related to Apache's Validate or Java 7's Objects. Basically all three implementations provide means to check preconditions. This is especially useful to check passed in arguments to fail-fast. At smartics we provided our own version of argument checking some time ago. It is called Arguments and is especially helpful to check for non-null or non-blank values.
The Idea for a Change
There is an interesting feature in Google's Preconditions class that we do not cover in our library: It returns the checked value. This makes it possible to reformulate the following
public MyConstructor(final String string, final Integer integer) {
Arguments.checkNotBlank("string", string);
Arguments.checkNotNull("integer", integer);
this.string = string;
this.integer = integer;
}
to
public MyConstructor(final String string, final Integer integer) {
this.string = Arguments.checkNotBlank("string", string);
this.integer = Arguments.checkNotNull("integer", integer);
}
This makes the code half as long.
Returning the value also allows to use the check in constructor chaining situations. It may get ugly, but in some situations it may make the failure condition more clear:
public MyConstructor(final String myDomainIdentifier) {
this(new Whatever(
checkNotBlank("myDomainIdentifier", myDomainIdentifier)));
}
This might get a better message in the exception if Whatever simply refers to a string, since the constructor above still ‘knows’ the name of the parameter to include it in the error message.
Now go for it!
Both scenarios I want to support in the next version of our library. I still want to stick to our version of the argument checking helper class, because I often have to check for argument values not being blank.
So all I have to do is return the passed in argument? “Wrong!” you shout and you are right.
If I change
public static void checkNotBlank(final String name,
final String value, final String message)
throws BlankArgumentException {
if (StringUtils.isBlank(value)) {
throw new BlankArgumentException(name, message);
}
}
}
to
public static String checkNotBlank(final String name,
final String value, final String message)
throws BlankArgumentException {
if (StringUtils.isBlank(value)) {
throw new BlankArgumentException(name, message);
}
return value;
}
}
This change does not break the source code. But I introduce an incompatible change with the previous version that occurs at runtime. This is because changing the return value requires the compiler to create a new method and removing the old. So the change is not binary compatible.
The relevant part in the Java Language Specification:
Changing the result type of a method, replacing a result type with void, or replacing void with a result type has the combined effect of deleting the old method and adding a new method with the new result type or newly void result (see §13.4.12).
For purposes of binary compatibility, adding or removing a method or constructor m whose return type involves type variables (§4.4) or parameterized types (§4.5) is equivalent to the addition (respectively, removal) of the an otherwise equivalent method whose return type is the erasure (§4.6) of the return type of m.
Java Language Specification, 13.4.15 Method Result Type
For more information about this topic, please refer to polygenelubricants‘s answer to the question Retrofitting void methods to return its argument to facilitate fluency: breaking change? on StackOverflow.
This problem is reported by the clirr-maven-plugin that can easily be integrated into any Maven build process.
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>clirr-maven-plugin</artifactId>
<version>2.3</version>
<configuration>
<minSeverity>info</minSeverity>
</configuration>
</plugin>
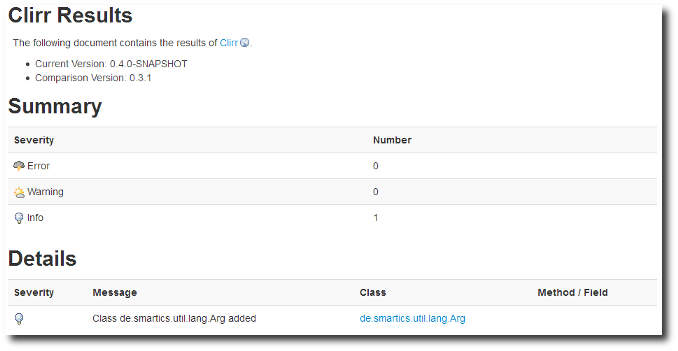
The report for the incompatible change looks like this on the Clirr report on the project’s Maven Site:
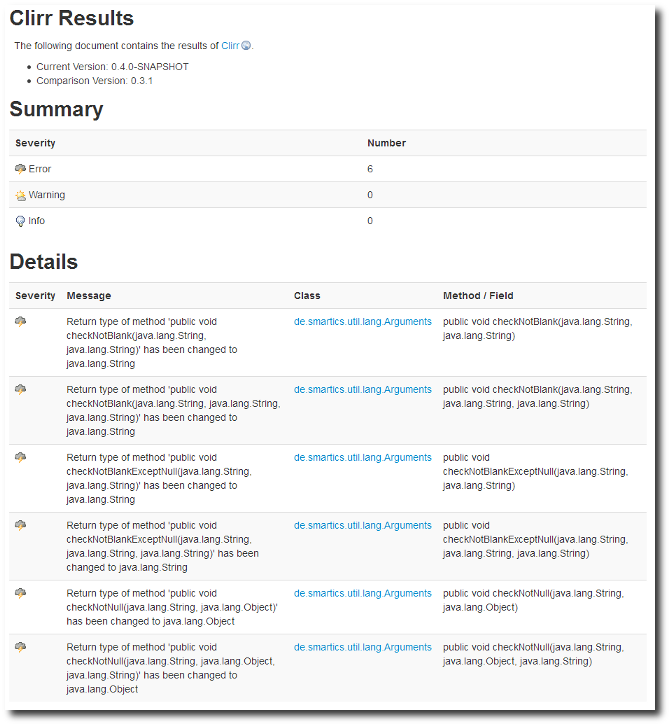
The fix in our case is quite easy if you control all dependent projects: You simply have to recompile. No source code change is required. But in reality this is not feasible. Either you do not have all dependent binaries in your control or you just do not have the resources to recompile and test them all. So the solution to this problem is to be found elsewhere.
Do not break Things
For libraries we have to be very sensitive to changes that break the API. In larger projects there may be a couple of modules that depend on the same library and if there is a change that broke the API all modules have to grade up to work properly together again. Therefore for e.g. Apache makes it easy to use their version 3 of commons-lang alongside with their version 2.
First they provided a new artifact ID:
<dependency> <groupId>commons-lang</groupId> <artifactId>commons-lang</artifactId> <version>2.6</version> </dependency>
<dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.1</version> </dependency>
This allows Maven to resolve a dependency set that includes both libraries. This way some modules can use the new version and other modules can update as soon as they want to.
To succeed in this, the package name has also be adjusted. Where in Version 2 the package for e.g. the Validate class mentions above was
org.apache.commons.lang.Validate
in Version 3 it is called:
org.apache.commons.lang3.Validate
So the library in version 3 can live along with any previous version, since Validate is effectively a new class.
Mark as deprecated
But in our case we do not have to go this far. We are not planning to release a new major version any time soon. Therefore we have to introduce a new class with the new behavior. It is called Arg. The old Arguments class is now marked deprecated.
/**
* Utility class to check arguments.
*
* @deprecated Due to a breaking change a new class called {@link Arg} has been
* designed to be used from now on. It has the same methods as this
* one, but it returns the value passed in to check. This allows to
* do the check and an initialization (e.g. in a constructor) in one
* line. It also allows to check arguments if another constructor is
* called (such as in <code>this()</code> and <code>super()</code>).
* This class is planned to be removed with the release of version
* 2.0.
*/
@Deprecated
public final class Arguments {
...
}
We inform our API users
- where the new version can be found
- why we made the change
- when this class will go out of service
The deprecation mark is translated into a warning by the compiler. If a developer is in doubt whether to use Arguments or Arg she simply has not remember which is newer. This helps to move the code towards the new version supported by the compiler.
The non-breaking change is reported in the Clirr report like this:
 Everything green again. No headaches for anyone in the future.
Everything green again. No headaches for anyone in the future.
Using complex data types in Maven plugin configurations is quite easy. There is a good and brief documentation within the Maven site that shows how to use them in your plugin: Mapping Complex Objects in Guide to Configuring Plug-ins.
What is not mentioned in this document is how the properties are injected. It seems that setters are used, if they are present. If not, injection occurs with the fields via reflection. So the following two configuration approaches are successful.
Field Injection
This example shows field injection together with a property type that is defined within the plugin’s project.
Configuration
The key contains (for simplicity) only one element, an identifier of the environment.
<configuration>
<key>
<environment>test</environment>
</key>
</configuration>
Mojo Implementation
The field is required to be named key.
public final class MyMojo extends AbstractMojo {
/**
* @parameter
*/
private Key key;
...
}
Property Type Implementation
It is important that the name of the type matches that of the parameter in the Mojo (the first letter is capitalized as is standard for Java Beans).
public class Key {
private String environment;
public String getEnvironment() {
return environment;
}
}
There is no setter, so Maven injects the value in the private field environment. The name of the field and the name of the property within the configuration are the same.
Setter Injection
This setter injection example shows the configuration of a property (a factory), whose type is defined outside of the Maven plugin project. The implementation attribute allows to select an implementation that is used as a complex property.
Configuration
The configuration references an implementation of the PropertySinkFactory interface.
<configuration>
<propertySinkFactory
implementation="de.smartics.properties.config.transfer.filesystem.Factory">
<targetFolder>${basedir}/target/testme</targetFolder>
<outputFormat>xml</outputFormat>
</propertySinkFactory>
</configuration>
Mojo Implementation
There is no naming constraint.
public final class MyMojo extends AbstractMojo {
/**
* @parameter
*/
private PropertySinkFactory<?> propertySinkFactory
...
}
Property Type Implementation
There are no constraints on the property type name. The properties of the type have to match the element names of the configuration (e.g. targetFolder).
package de.smartics.properties.config.transfer.filesystem;
import java.io.File;
import java.io.IOException;
import de.smartics.properties.api.config.transfer.PropertySinkFactory;
import de.smartics.util.io.FileFunction;
public final class Factory implements
PropertySinkFactory<FileSystemPropertySink>
{
private File targetFolder;
private PropertiesFormat outputFormat = PropertiesFormat.NATIVE;
public Factory() {
}
public void setTargetFolder(final String targetFolder) {
this.targetFolder = new File(targetFolder);
try
{
FileFunction.provideDirectory(this.targetFolder);
}
catch (final IOException e)
{
final String message =
String.format("Cannot create target folder '%s'.",
this.targetFolder.getAbsolutePath());
throw new IllegalArgumentException(message, e);
}
}
public void setOutputFormat(final String outputFormat) {
this.outputFormat = PropertiesFormat.fromString(outputFormat);
}
...
}
The example shows how String parameter values are translated to their domain types within the setter methods.
Conclusion
The examples show more detailed than the original documentation how complex properties can be used in Maven plugins.
![]() As developers we do not want to hard code values in our source code.
As developers we do not want to hard code values in our source code.
int iterations = 42;
Static analyzers, like Checkstyle tell us that we should not use magic numbers.
'42' is a magic number.
And defining these values as constants does help to appease the static analyzer, but the value is still hard coded.
public static final int DEFAULT_ITERATIONS = 42;
public void method() {
int iterations = DEFAULT_ITERATIONS;
...
}
For a Java developer, any change to the value requires to recompile the sources. And not only the source code with the declaration of the constant, but every source file that references this constant. Changing the value of a public constant is usually a bad idea. So the constant is not a property, since it should not be changed at development time and cannot be changed during runtime.
Happy Hacking with Properties
To work around this, a Java developer may use Properties. So here is the quickhack:
public void method() throws IOException, NumberFormatException {
final Properties properties = loadProperties();
final int iterations = readAsInt(properties, "defaultIterations");
...
}
public Properties loadProperties() throws IOException {
final Properties properties = new Properties();
final InputStream input =
getClass().getResourceAsStream("app.properties");
if (input != null) {
try (final BufferedInputStream bin =
new BufferedInputStream(input)) {
properties.load(bin);
}
}
return properties;
}
private int readAsInt(final Properties properties, final String key)
throws NumberFormatException {
final String stringValue = properties.getProperty(key);
if (stringValue != null) {
final int intValue = Integer.parseInt(stringValue);
return intValue;
}
return 0;
}
Additionally a properties file named app.properties is supplied within the classpath of the project to make this code work.
So why is this a quickhack?
- The properties file is part of the classpath. Therefore the code does not have to be recompiled, but repackaged. The problem is that in this example the configuration is shipped with your code. You can easily work around this, if you provide your configuration in its own JAR. This is easily overlooked, since many Java Standards demand that the configuration is packaged with the code (e.g. te
web.xmlin a WAR file). - The properties are easily managed by the developer, who edits the value and saves it to the source code management system. This is a pretty good idea, since this way the property value changes can be tracked and different versions of configuration can be compared. But configuration values are not so easily edited by the operations team that has to open the properties file from within JAR file with their text editors. It depends on your use case, if this is a problem.
- The property may be changed during runtime in the in-memory representation of the properties, but it may be challenge to persist such a change.
- You find no error handling in this code. What if the property or the whole properties file is missing? Is it ok to return 0 as default?
- Bad traceability: in case the property value is not an integer, an exception is raised. Further work should be invested to tell which property has a wrong type of value. What is missing is a proper value conversion. And in the code above there is just the conversion to integer. What about the other primitive types? What about URIs or even more complex types?
- But even if the value can be parsed as an integer, there may be constraints on the value. Is a negative value for an iteration count really allowed? What is missing is a proper validation of the value.
- Where is the validation code put? Crafting it manually requires some form of integration pattern, maybe boilder plate code. If you are implementing a business function, you surely do not want to bother with such basic tasks.
- This code has to be tested. On the bottom line code and configuration is the same. A configuration is an externalized, configurable piece of code.
- A configuration file is part of the public interface. We mentioned above, that values passed in have to be converted and validated. What is still missing is a documentation that tells users of the system which values are allowed and what default values are provided. It should also tell which properties are mandatory and which optional. Which are read only and which can be changed at runtime. And there is even more metadata. This documentation has to be kept in sync with the implementation. The number of iterations may be limited to a maximum number in future.
- And in the end we added another magic value: The name of the property. This has to be added as a constant as we cannot add the key to a properties file. So again it needs to be decided where these property keys should be defined.
- A developer should not bother with the administration of properties. Neither where to put them, nor how to load them. Handling properties is an architectural decision. There should be a documented way on how to deal with properties in a given project. Everyone will happily adhere to these rules instead of inventing the wheel over and over again. Not only within a project, but also from project to project.
The Properties class is basically a hashtable with load and store functions. There are certainly use cases for Properties, but for many more use cases this Java class provides too basic support for application developers.
Some Elaboration with Preferences
The Properties class is well known. Less known is the Preferences package. The Preferences class within this package provides some interesting features.
- The user of this class does not bother where to pick the property values from. This is handled by an implementation that usually extends AbstractPreferences and is registered via a PreferencesFactory. Java also provides a default implementation (that may or may not suit your needs).
- If you need it, there is support for user and system properties.
- There is even an event mechanism that allows to register code to be notified of value changes.
- Value changes are stored transparently by the implementation.
- There is a conversion support for all basic types.
So this class cures some of the problems above, but not all. The developer still has to care for:
- Validation
- Basic Testing
- Key Handling
- Documentation
- Handling complex types
smartics-properties
If you do not want to invest in providing a technical basis for handling properties in your application, you may have a look at a configuration library. There are many open source versions on the internet. smartics Properties is one of them. Please note that this library is currently in an early version.
![]() The Maven plugin Hibernate 4 Maven Plugin has been released with version 0.2.0.
The Maven plugin Hibernate 4 Maven Plugin has been released with version 0.2.0.
Thanks to the contribution of Jean Dannemann Carone the plugin provides a new feature to configure a naming strategy for Hibernate.


